Menu
Qu'est-ce qu'un beau code, pour un LLM ?
- GPT-5.1 a une signature stylistique stable : dans cette expérience, il pousse les snippets vers un style proche de Clean Code, quel que soit le code de départ.
- Même sur du code déjà propre, il continue de modifier environ 10 % des lignes à chaque passage : il ne s’arrête pas spontanément.
- Sur les noms, il oscille entre deux équivalents au fil des itérations.
Chaque développeur a sa propre idée de ce qu’est un beau code.
Il y a ceux qui veulent des méthodes courtes, quitte à les multiplier. Ceux qui préfèrent des méthodes longues mais cohérentes. Ceux pour qui un commentaire bien placé sauve une vie, et ceux qui considèrent qu’un bon code n’a pas besoin de commentaires. Il y a des écoles. Robert C. Martin a fait carrière sur l’une d’elles avec Clean Code. Kent Beck sur une autre. Et des équipes entières se déchirent depuis des années sur ces questions.
Une question qu’on s’est rarement posée avec précision : et les LLMs, ils ont quel style ?
On sait bien qu’ils ont des préférences. Quand on demande à GPT, Claude ou Gemini de générer du code, on voit assez vite des patterns. Mais c’est anecdotique. Personne, à ma connaissance, n’avait fait une étude vraiment systématique de la signature stylistique d’un LLM. Combien de méthodes en moyenne ? Combien de commentaires conservés ? Combien d’identifiants renommés ?
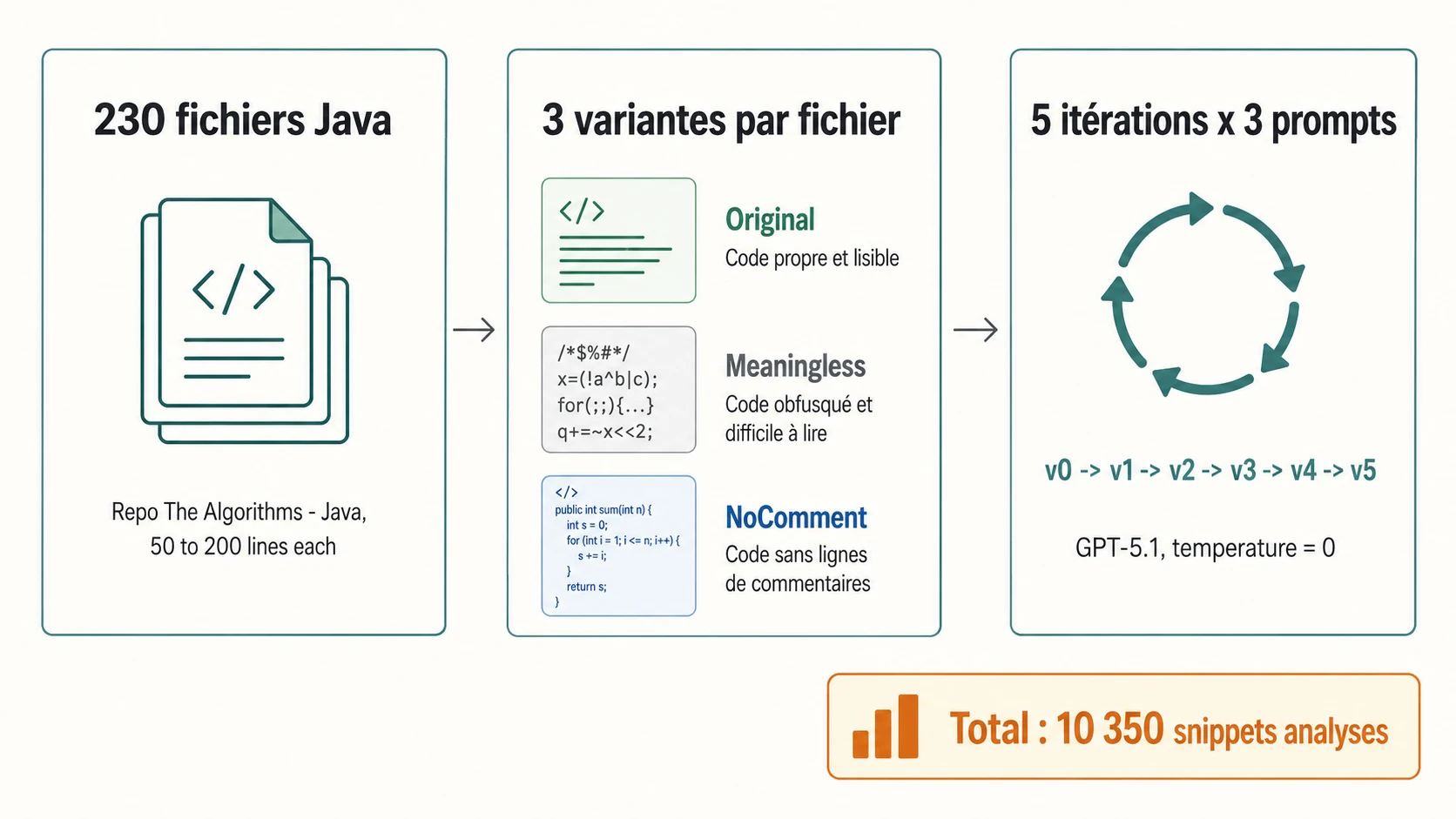
Trois chercheurs de l’université de la Sarre (Norman Peitek, Julia Hess et Sven Apel) viennent de publier sur arXiv un papier qui répond à cette question. Le titre est From Restructuring to Stabilization: A Large-Scale Experiment on Iterative Code Readability Refactoring with Large Language Models. L’idée est simple : prendre 230 snippets Java, demander cinq fois de suite à GPT-5.1 de les refactoriser pour améliorer la lisibilité, et regarder ce qui se passe.
Le résultat est, à mon avis, l’un des plus utiles de ces derniers mois pour qui utilise des LLMs en production. Et le point important n’est pas que GPT-5.1 refactorise. C’est qu’il refactorise toujours dans une direction reconnaissable - la sienne.
Le protocole
Source : Peitek, Hess & Apel, arXiv:2602.21833, 2026.
Les auteurs ont pris 230 fichiers Java du dépôt GitHub The Algorithms – Java, un repo éducatif d’implémentations d’algorithmes classiques. Le choix n’est pas anodin : code idiomatique, conventions homogènes, licence MIT donc reproductible. Ils ont filtré pour ne garder que des fichiers entre 50 et 200 lignes, avec au moins 50 % de code (pas que des commentaires).
À partir de chaque fichier, ils ont créé trois variantes :
- Original : le code tel quel, propre, idiomatique.
- Meaningless : tous les identifiants (classes, méthodes, variables) ont été remplacés par des noms sans signification. Tous les commentaires ont été rendus aléatoires. La structure du code est préservée mais sa lisibilité humaine est volontairement détruite.
- NoComment : tous les commentaires sont retirés, sans rien d’autre toucher.
Ensuite, pour chaque variante, ils ont demandé à GPT-5.1 (temperature = 0, donc déterministe) de refactoriser le code cinq fois de suite, en utilisant trois formulations de prompt :
PromptGeneral: « Refactor this code for improved readability. »PromptMeaning: « Refactor this code for improved readability, especially with respect to identifier naming. »PromptComments: « Refactor this code for improved readability, especially with respect to comments. »
Total : 230 snippets × 3 variantes × 3 prompts × 5 itérations = 10 350 snippets produits par le modèle. Un outil de diff fin (DiffParser) catégorise ensuite chaque ligne changée : rename, syntaxe seule, changement de commentaire, modification de code, ou changement mixte.
Étude de bonne taille, et surtout très bien instrumentée.
Découverte 1 : Une dynamique en deux phases
Pourcentage de lignes inchangées à chaque itération
Variante Original, PromptGeneral. Source : Peitek et al., 2026.
Il y a deux phases distinctes dans le processus, et c’est reproductible.
À la première refactorisation (v0 → v1), GPT-5.1 touche beaucoup de code. Seulement 45 % des lignes restent inchangées. Il renomme, casse en plusieurs méthodes, supprime des commentaires, en ajoute d’autres, change le format. C’est une vraie restructuration.
À la deuxième itération (v1 → v2), c’est déjà différent. 76 % des lignes ne bougent plus. Les changements deviennent locaux, chirurgicaux.
À partir de la troisième, on entre dans une phase de stabilisation : 86 %, 89 %, puis 92 % de lignes inchangées entre versions successives. Le modèle a trouvé sa version « finale » et n’y touche plus qu’à la marge.
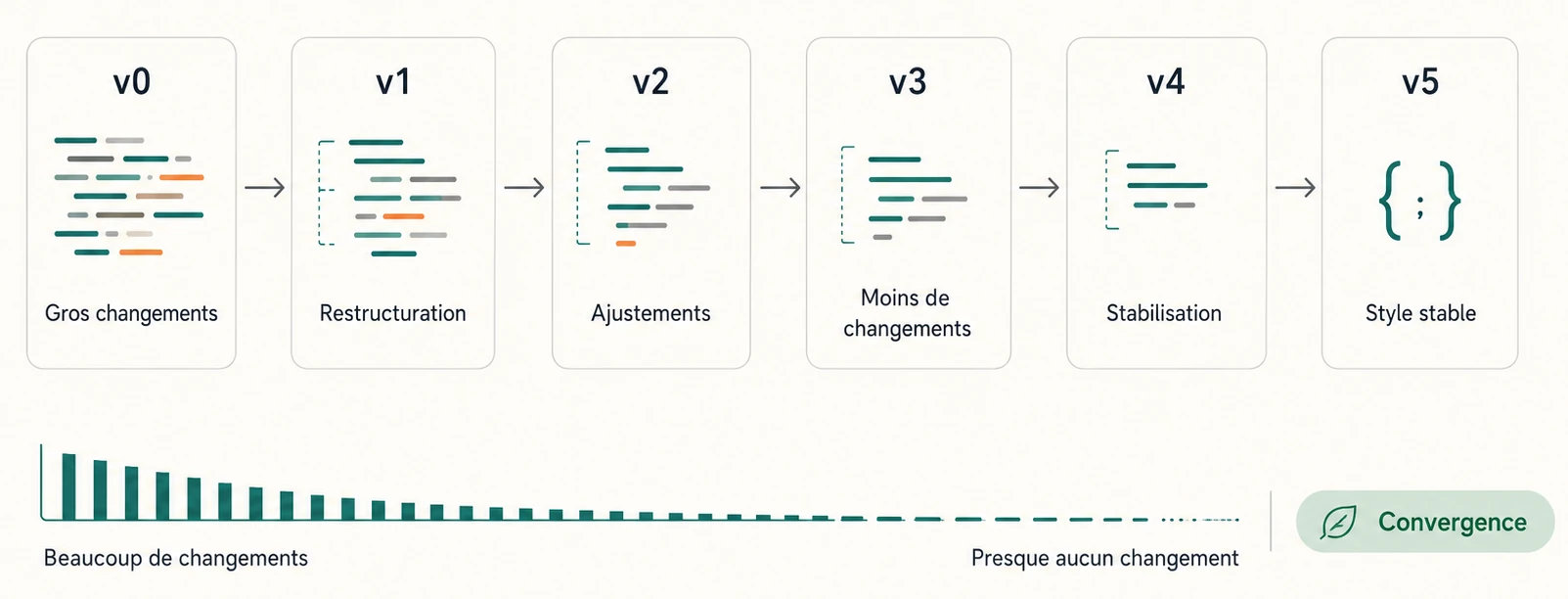
Première information utile : un refactoring LLM n’est pas un processus convergent rapide. Il y a une vraie phase de restructuration qui mobilise une à deux itérations. Si on demande à GPT de refactoriser une fois et qu’on compare au résultat, on voit beaucoup de changements. Si on lui redemande, on voit encore beaucoup de changements - mais d’une autre nature. Ce n’est pas la même chose, et pour qui industrialise du refactoring assisté, la distinction change tout.
Découverte 2 : Le LLM converge, indépendamment du point de départ
Convergence du % de lignes inchangées : les trois variantes
Pourcentage de lignes inchangées par transition. Les trois courbes finissent dans la même zone (~89-92 %). Source : Peitek et al., 2026.
C’est ici qu’on entre dans le résultat le plus contre-intuitif du papier.
Pour vérifier si la convergence observée est vraie (et pas un artefact du code de départ), les auteurs ont mesuré ce qui se passe avec les variantes Meaningless et NoComment. Souvenez-vous : Meaningless est volontairement illisible, NoComment a perdu tous ses commentaires.
Si le modèle se contentait de polir le code qu’on lui donne, on s’attendrait à ce que les trois variantes restent différentes après cinq itérations. La Meaningless aurait des noms peu informatifs, la NoComment aurait peu de commentaires. Logique.
Ce n’est pas du tout ce qui se passe.
Les trois variantes convergent vers des représentations très proches après cinq itérations. Sur le nombre de méthodes : les trois partent à 3,1 méthodes en moyenne (même structure de base) et finissent toutes autour de 6 méthodes après cinq refactorings. Sur le nombre de lignes de code : les trois partent à 56 lignes et finissent autour de 73. Sur les commentaires inline : Original et Meaningless partent à 1,3, et toutes les variantes convergent vers 0,2 - quasi-élimination.
Le LLM a une représentation interne de ce qu’est du « code lisible ». Cette représentation existe - elle est démontrée empiriquement par la convergence. Et elle ne dépend que marginalement du code de départ.
Le LLM ne se contente pas de polir le code qu’on lui donne en respectant son style. Il le pousse vers son propre style. Et cette « cible » est suffisamment stable pour que, partant de trois codes très différents, on aboutisse à trois codes très proches.
Déléguer le refactoring à un LLM, ce n’est pas neutre stylistiquement. C’est adopter implicitement le style du modèle.
Découverte 3 : La signature stylistique de GPT-5.1
Signature stylistique GPT-5.1 : après 5 itérations
Moyennes sur 230 snippets Java, variante Original, PromptGeneral. Source : Peitek et al., 2026.
Sur les 230 snippets refactorisés cinq fois, voici les tendances mesurées :
- Le nombre de méthodes est passé en moyenne de 3,1 à 6 par fichier. Presque doublé. GPT-5.1 croit à la décomposition. Une longue méthode devient plusieurs petites.
- Le nombre de lignes de code augmente régulièrement à chaque itération, de 58 à 73. Le découpage en plus de méthodes ne se fait pas à coût zéro : signatures supplémentaires, appels, parfois paramètres.
- Les commentaires inline (du type
int x = 0; // counter) sont quasiment éliminés. De 1,3 à 0,2 en moyenne. - Les lignes vides augmentent progressivement. Le code devient plus aéré, plus respirable visuellement.
- Les identifiants sont normalisés vers des conventions Java standard (camelCase, noms longs et descriptifs, suffixes explicites comme
Counter,Result,Helper).
Méthodes courtes et nombreuses, suppression des commentaires inline, aération à la PEP-8, noms longs et descriptifs : dit autrement, et en forçant un peu le trait, dans cette expérience, GPT-5.1 se comporte comme un disciple de Clean Code. On peut raisonnablement soupçonner que ce type de littérature a influencé les patterns appris, sans pouvoir le démontrer.
Ce qui compte ici, c’est la netteté du pattern - reproductible, mesurable, sur 230 codes différents. Et c’est précisément ce qui rend le sujet sensible : beaucoup d’équipes ne se reconnaissent pas dans Clean Code, et se retrouvent malgré tout à recevoir ce style en sortie de leur LLM.
Découverte 4 : Le LLM ne sait pas s’arrêter
Similarité entre versions successives : code déjà propre
Variante Original. Même sur du code propre, GPT-5.1 continue de modifier ~10 % des lignes à chaque passage. Source : Peitek et al., 2026.
Sur la variante Original (code déjà propre, déjà idiomatique), on s’attendrait à ce que le modèle laisse tranquille. Ce n’est pas ce qui se passe. La similarité entre versions successives s’approche de 0,90 à la fin, mais ne touche jamais le plafond. Le modèle ne s’arrête pas spontanément.
Les auteurs appellent ça une tendance au sur-refactoring : quand on demande de refactoriser, le modèle refactorise, même quand il n’y a rien à faire. Pour qui industrialise ce type de flux, c’est un problème concret. Modifier du code qui n’en avait pas besoin, c’est du risque de bug, du bruit dans le git blame, de la friction en revue.
La parade est connue mais peu utilisée : il faut des critères d’arrêt explicites. Ne pas dire « refactorise », mais « refactorise si nécessaire, sinon réponds inchangé ». Et même comme ça, le résultat n’est pas garanti.
Découverte 5 : L’effet « rename oscillation »
Oscillation d'un identifiant sous PromptMeaning
Exemple représentatif. Le modèle alterne entre deux noms équivalents au fil des itérations, sans amélioration nette. Source : Peitek et al., 2026.
Avec le prompt PromptMeaning (qui cible explicitement les noms), un phénomène inattendu apparaît : les noms oscillent. Le modèle choisit un nom en v1, le change en v2, revient au premier en v3. Pas systématique - mais suffisamment fréquent pour être documenté comme un risque structurel.
L’explication probable : sans guide externe (convention d’équipe, dictionnaire de domaine), le modèle hésite entre plusieurs noms équivalents. Le contexte change légèrement à chaque itération (d’autres lignes ont bougé), et son arbitrage bascule. Un dev senior trancherait une fois et s’y tiendrait. Le LLM, lui, peut changer d’avis.
Pour qui industrialise ce flux, c’est un signal d’alerte : les diffs successifs sont bruités par des changements qui ne correspondent à aucune amélioration. Le type de bruit qui pollue les revues et érode la confiance dans l’outil.
Découverte 6 : Le prompt influence le détail, pas la trajectoire générale
Les auteurs ont testé trois prompts différents (PromptGeneral, PromptMeaning, PromptComments) pour voir si la formulation change quelque chose à la dynamique de refactoring.
Le résultat est nuancé. Les prompts ciblés influencent bien le type de changements introduits - PromptMeaning produit plus de renames, PromptComments produit plus de modifications de commentaires. Mais la dynamique globale (restructuration puis stabilisation, convergence vers le même idéal stylistique, sur-refactoring résiduel) est la même quelle que soit la formulation.
Rassurant, parce que le prompt garde un effet local : on peut bien orienter les renames ou les commentaires. Inquiétant, parce qu’il ne suffit pas à changer la trajectoire stylistique de fond : on peut demander gentiment, insister, préciser, le modèle reviendra toujours vers son idée du beau code.
Ce que ça éclaire pour moi
On mesure déjà la complexité. On mesure déjà le couplage. Mais on mesure encore mal la cohérence stylistique structurelle d'une codebase. Et c'est précisément là que les LLMs vont laisser leurs traces.
La maintenabilité d’un projet tient aussi à la cohérence stylistique interne de sa codebase. Une codebase où toutes les méthodes sont longues mais cohérentes est plus facile à maintenir qu’une codebase qui mélange des fichiers façon Clean Code et des fichiers façon « grosse fonction utilitaire de 200 lignes ». Le cerveau du développeur s’habitue à un style - c’est ce qui permet de naviguer rapidement, de prévoir où trouver quoi, de reconnaître l’inhabituel.
Introduire un LLM dans le flux de refactoring d’une codebase existante, c’est prendre le risque de fragmenter ce style interne. Les fichiers qu’il touche migrent vers sa cible à lui. Les autres restent dans l’idéal historique de l’équipe. La codebase devient un patchwork (méthodes de cinq lignes ici, de cinquante là) sans que les métriques classiques en montrent quoi que ce soit. La complexité cyclomatique moyenne peut être identique. Le couplage peut ne pas avoir bougé. Mais la cohérence s’érode, silencieusement.
C’est là le vrai trou dans nos outils. PhpMetrics, AstMetrics, les linters et les formateurs ont été construits pour quantifier la maintenabilité - mais via des métriques absolues (complexité, couplage) ou de surface (mise en forme). La dispersion stylistique structurelle (variance du nombre de méthodes par fichier, des longueurs de méthodes, des conventions de nommage, de la densité de commentaires) reste largement non mesurée. Et c’est précisément le terrain où les LLMs vont laisser leurs traces.
Ce que ça implique, concrètement
Quatre choses ressortent.
Un LLM a un style, et il faut le documenter. Si l’équipe utilise GPT-5.1 pour refactoriser, elle pousse vers Clean Code. Si elle utilise Claude, le style est différent. Si elle utilise Qwen ou Mistral, idem. Avant de déléguer du refactoring, il est utile d’avoir une idée de la signature stylistique du modèle utilisé - et de décider si elle est compatible avec celle de la codebase.
Des critères d’arrêt explicites. Le sur-refactoring n’est pas un bug - c’est le comportement par défaut du modèle. Pour qu’il s’arrête quand il n’y a plus rien à faire, il faut l’inscrire dans le prompt. Refactorise uniquement si le code en a besoin. Si tu juges qu’il est déjà acceptable, réponds avec le code inchangé. Et même comme ça, vérifier en aval que les diffs sont réellement améliorants.
Préserver explicitement les commentaires qui ont de la valeur. Le modèle élimine systématiquement les commentaires inline, et c’est parfois une vraie perte. Un commentaire qui dit pourquoi (« on prend cette branche d’abord parce qu’elle est la plus fréquente en production ») a une valeur que le code ne véhicule pas. Si le flux LLM les supprime, on appauvrit la codebase.
Faire attention au naming. L’oscillation sur les noms est réelle et bruyante. Refactoriser plusieurs fois la même portion de code avec un LLM sans demander de réutiliser les noms existants revient à voir le même fichier renommer ses variables à chaque passage, sans amélioration nette.
Au-delà de ces points techniques, il y a une question plus large : qui définit le style de notre codebase ? Pendant des décennies, c’étaient les équipes humaines, à travers leurs revues, leurs guides internes, leurs disputes. Maintenant, si on n’y prend pas garde, c’est implicitement le LLM qu’on utilise - et donc les biais hérités d’un corpus d’entraînement dont la composition n’est pas neutre.
Que cette référence soit bonne ou mauvaise est un autre débat. Le point ici, c’est que c’est une décision par défaut (prise pour nous, sans nous) qui mériterait d’être consciente.
Limites et précautions de lecture
Le papier a plusieurs limites que les auteurs mentionnent honnêtement.
Un seul modèle testé. C’est GPT-5.1, et c’est GPT-5.1 uniquement. La signature stylistique de Claude, de Qwen, de Mistral est probablement différente. Une comparaison cross-modèles serait un prolongement naturel - c’est très probablement ce qui suivra.
Une seule langue testée, Java. Sur du Python, du PHP ou du Go, les patterns stylistiques préférés du modèle peuvent ne pas être les mêmes. Les conventions sont différentes par langage, et le modèle s’y adapte. Les chiffres précis (multiplier les méthodes par 2, augmenter de 26 % les lignes de code) ne sont pas directement transposables.
Un corpus académique. Les snippets du repo The Algorithms sont pédagogiques, courts, isolés. Le comportement sur du code de production réel (multi-fichier, avec des dépendances, des side-effects) n’est pas testé ici. On peut raisonnablement supposer que les grandes tendances tiennent, mais les chiffres précis ne sont pas garantis.
Le point important n’est donc pas de savoir si le style de GPT-5.1 est bon ou mauvais. Le point important, c’est qu’il existe.
Quand une équipe introduit un LLM dans son flux de développement, elle introduit aussi une préférence stylistique externe. On peut l’accepter. On peut la mesurer. On peut la contraindre. Mais il vaut mieux éviter de la subir sans s’en rendre compte.
OctoFirst
Voyez où votre équipe coince
Le projet sur lequel je bosse en ce moment. Vos pull requests en disent déjà long : où l'équipe se grippe, comment l'activité se répartit entre bugs, features et refacto. OctoFirst en fait des signaux clairs, sans reporting à faire à la main.
Y jeter un œil, c'est gratuitAudit & Formation
Disponible sur Malt
Besoin d'un regard extérieur sur votre code ? J'accompagne les équipes PHP sur l'architecture, les tests et l'industrialisation, au rythme de vos projets.
Me trouver sur Malt© Jean-François Lépine, 2010 - 2026 · Flux RSS