Menu
Qualité logicielle : comment fixer les valeurs limites ?
- Découvrez comment fixer des valeurs limites pour la qualité logicielle avec PhpMetrics.
- Suivez un processus en quatre étapes : théorique, pondération, analyse démographique et ajustements pratiques.
- Apprenez à adapter les métriques à la réalité des projets PHP pour améliorer la maintenabilité et la cohésion du code.
Plus j’avance dans la réalisation de PhpMetrics, plus une question se pose : je dispose de métriques sur le code source, mais à partir de quel moment alerter l’utilisateur ? Quelle est la valeur idéale ? Quelles sont les valeurs minimales et maximales ?
Je vous propose un petit retour d’expérience sur la manière dont j’ai tenté de fixer ces valeurs pour PhpMetrics. Ce qu’il faut savoir, c’est que j’ai procédé itérativement selon la manière suivante :
- utilisation de valeurs théoriques
- pondération de la théorie
- analyse démographique
- ajustement par l’expérience
Étape 1 : Utilisation de valeurs théoriques
La première méthode est la plus simple : la plupart des métriques logicielles que j’ai intégrées sont très bien théorisées, et de des suggestions de bornes maximales et minimales existent assez souvent.
Prenez LCOM4 par exemple. Cet indicateur (Lack of cohesion of methods) tend à révéler la cohésion d’une classe :
<?php
class Example {
private $a;
public function m1() {
$this->m2();
}
public function m2() {
$this->a = 1;
}
public function m3() {
$this->a = 1;
}
public function m4() {
$this->m5();
}
public function m5() {
echo 'ok';
}
}
Examinons les corrélations des méthodes de cette classe :
m1()appellem2().m2()partage avecm3un attribut communam4()appellem5()
Il y a donc deux flux de code bien distincts dans cette classe. On dit alors que LCOM4(Example) = 2.
Cet indicateur est à mettre en relation avec le S des principes SOLID (Single reponsability).
Les méthodes d’une classe qui servent une besoin commun s’articulent ensemble : elles s’appellent les unes les autres ou
partagent des attributs communs. Il est donc probable ici que notre classe possède au moins deux reponsabilités.
D’un point de vue purement théorique, la valeur idéale de LCOM4 d’une classe est donc de 1.
Étape 2 : Pondération de la théorie
Mais il ne faut pas oublier que ces indicateurs, bien que volontairement agnostiques, ont tout de même été fortement orientés par les langages de programmation utilisés pour les théoriser / illustrer.
Revenons à LCOM4, et à l’idéal théorique de LCOM4(classe) = 1.
Cet idéal signifie que toutes les méthodes d’une classes fonctionnent ensemble (principe de cohésion). Or la plupart des classes PHP comportent un très grand nombre de getters/setters, souvent inutilisés à l’intérieur de la classe même. Vu par un robot, les getters/setters méthodes semblent des méthdoes orphelines, et augmentent donc artificiellement LCOM4.
Cet aspect est propre aux langages qui ne comportent pas de sucre syntaxique pour les getters et setters. En C#, on pourrait simplement écrire
public int X { get; set; }
En PHP ce n’est pas encore le cas. il faut donc pondérer cet indicateur.
Il en va de même pour la majorité des indicateurs : le code écrit en PHP est assez typique : typique par le langage même, mais aussi par l’orientation des projets qui l’utilisent, assez souvent plus orientés production (court terme) plutôt qu’évolution (long terme).
Petite parenthèse utile : je ne cherche pas à polémiquer, juste à faire un constat. Ce constat pourrait tout à fait être identique pour d’autres langages de programmation. Oui, je sais qu’il y a d’excellents projets PHP, orientés très long terme. Mais je pense ici faire un constat d’ordre général selon mon expérience. Bref, j’essaye d’être pragmatique.
Étape 3 : Analyse démographique
Il m’a donc fallu trouver un moyen de déterminer de nouvelles bornes, proches de la téhorie, mais plus adéquates à PHP.
Le plus simple m’a semblé de faire une analyse démographique de projets PHP. Idéalement de projets représentatifs. Coup de chance, packagist fournit la liste des paquets les plus utilisés. Je me suis donc mis à les analyser.
[Spoiler] La première chose à comprendre est que cette analyse est biaisée :
- les projets sont open source. Ils sont fait par des volontaires, avec un processus souvent plus qualitatif (revue de code) que des projets d’entreprise
- les projets recensés sur packagist sont ceux qui sont déclarés comme paquet Composer. Ils sont donc, pour la plupart, très récents.
- les projets open source concernent généralement de l’outillage (composants, frameworks, librairies…). Ils ne sont pas représentatifs de projet fonctionnement complexes
[/Spoiler]
Je reviendrai sur ces aspects par la suite. En attendant, je pense que cette analyse, bien que biaisée, reste pertinente si on la prend pour ce qu’elle est, et rien de plus : une analyse de projets bien spécifiques, représentatifs d’une partie seulement des typologies de projets possibles.
Le processus d’analyse est le suivant :
- Téléchargement des sources
- Exécution de l’analyse sur un échantillon représentatif (environ 5 000 classes)
- Aggrégat des résultats
- Elimination des extrêmes (par écart interquartile)
- Analyse des percentiles de chaque série
Je me suis alors retrouvé avec des résultats de ce type :
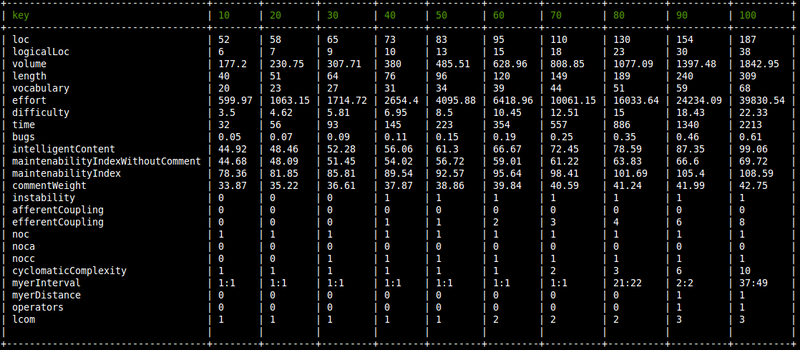
Par tâtonnements, il m’a paru judicieux de considérer comme :
- borne inférieure => le trentième percentile
- borne supérieure => le quatre vingtième percentile
- borne supérieure maximale => le quatre vingt dixième percentile
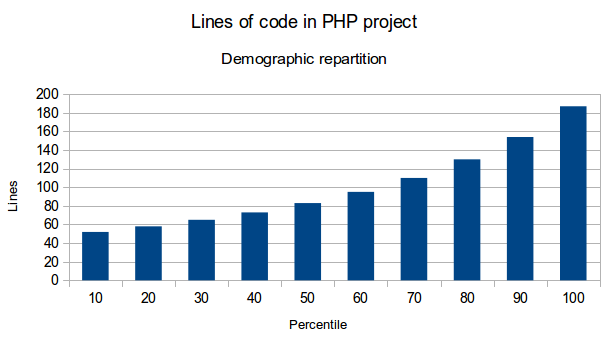
Dans le cas du nombre de lignes de code, il en ressortirai qu’un fichier doit contenir idéalement entre 65 et 130 lignes de code, et au maximum 154. Ces chiffres ne semblent pas absurdes.
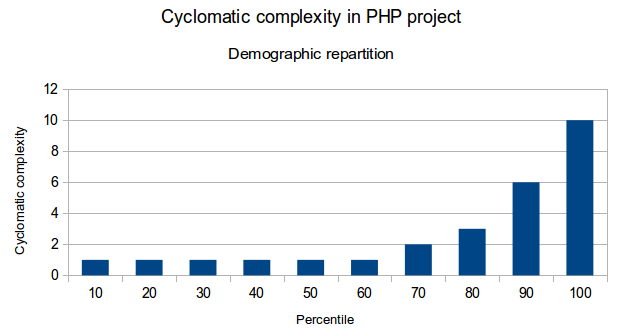
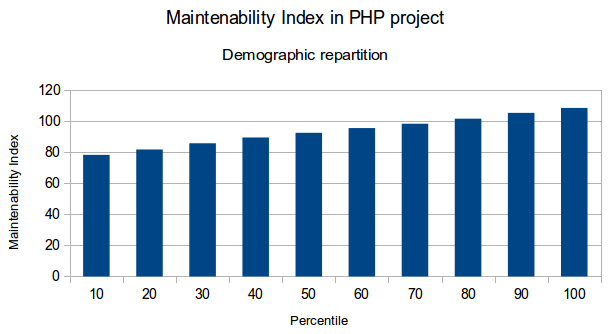
Voici quelques graphiques qui illustrent ces résultats:
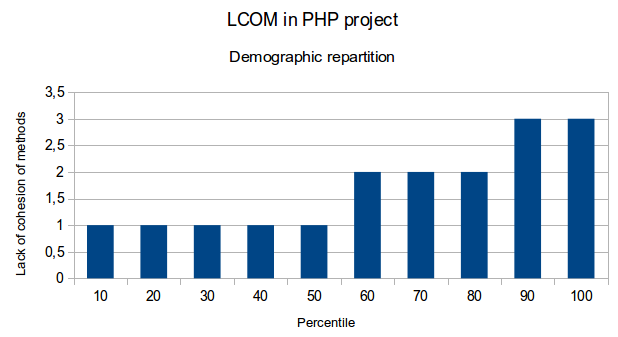
Étape 4 : Ajustements par l’expérience
Je l’ai dit : l’analyse démographique, bien qu’intéressante, est faussée : elle ne considère que certains types de projets (généralement des outils).
Dans la vraie vie, la plupart des codes sources sont “en dehors de clous”. Facile d’avoir une complexité cyclomatique faible quand on n’a pas de délais, qu’on ne gère pas de changements fonctionnels fréquents ou qu’on ne gère pas de règles métiers…
J’ai donc confronté ces indicateurs à mon expérience. J’ai en effet la chance de réaliser des audits chez de nombreux clients, ce qui me permet d’être confronté à des projets très variés et nombreux . J’ai donc systématiquement analysé le code des projets auxquels j’ai été confronté, et ce depuis que je suis développeur (ou presque).
Attention, là encore l’analyse est biaisée : quand on fait appel à un consultant, c’est en général que le projet subit des avaries, souvent dûes à des problèmes techniques (code peu évolutif, architecture mal adaptée…). Le code de ces projets est donc généralement moins maintenable que sur des projets où tout se passe bien (même si ce n’est pas systématiquement le cas). On est donc dans la situation inverse des projets Open Source précédemment mentionnés.
J’ai donc réajusté les indicateurs en fonction de ces analyses, et continue de les réajuster au fur-et-à-mesure.
Conclusion
Enfin, un point important reste à soulever. C’est d’ailleurs cet aspect qui m’a fait hésiter à fournir des indicateurs visuels (rouge pour “critique”, jaune pour “à examiner” et vert pour “probablement correct”) : aucune borne, aucune limite n’est universelle.
Lorsqu’on analyse un Controlleur, il est évident qu’on ne s’attend pas à avoir le même Vocabulaire que dans un Service. Une Entité n’aura pas le même Indice de maintenabilité qu’un Validateur…
La conclusion de ces analyses est donc assez triviale : c’est à l’humain de pondérer les chiffres. Un outil d’analyse ne fournit que des indicateurs, pas des vérités.
Attention, il ne faut pas pour autant rejeter tout outil d’analyse statique (comme on le fait malheureusement trop souvent). Ces indicateurs sont pratiques et indispensables si on sait les interpréter et les prendre pour ce qu’ils sont : des indicateurs. Ce qui compte, ce n’est pas de savoir si telle classe ou telle fichier a une complexité trop élevée. Non, ce qui est important c’est de surveiller et de tenir compte de l’accumulation d’indicateurs et de leur orientation générale.
Si une classe a un peu trop de lignes de code ce n’est pas grave ; si les classes d’un paquet ont une Complexité cyclomatique élevée, une LCOM élevée, un Indice de maintenabilité faible… là il faudra écouter les tendances des indicateurs, et se pencher sur le code en question pour comprendre ce qui peut causer ces remontées.
**L'analyse statique n'est pas une diseuse de vérité, mais un un outil d'alerte**
© Jean-François Lépine, 2010 - 2026 · Flux RSS