Menu
Boostez vos Échanges de Données entre Services : DataBus, RabbitMQ et Protobuf
- Découvrez comment structurer et standardiser vos échanges de données entre micro-services avec RabbitMQ, Protobuf et un modèle simple Sujet-Verbe-Prédicat.
- Apprenez à optimiser la diffusion via des échanges et queues pour un traitement efficace et scalable, tout en évitant les dépendances complexes.
- Inspirez-vous d’exemples concrets : suivi d’activité en temps réel, moteur de recommandations, synchronisation inter-systèmes. Un guide clair pour booster la robustesse et la lisibilité de vos flux de données métier.
Je vous propose de parler un peu de Bus de données. Un bus de données permet de transférer des données entre plusieurs logiciels. Par exemple, entre une application web et un moteur de traitement en masse de données (Big Data). Ou encore entre deux micro-services.
Nous utilisons RabbitMQ et PHP pour nos bus. Ce n’est pas forcément les technologies les plus adaptées dans votre cas, mais ça reste très pratique à mettre en œuvre et couvre bien nos besoins.
Triplets, et un peu de grammaire
Au quotidien, dans notre architecture CQRS, tout événement métier sur nos sites web déclenche l’émission d’un message RabbitMQ.
Par exemple (en schématisant) voici le code lorsqu’on veut dépublier une offre d’emploi sur l’un de nos sites :
<?php
$event = new JobPostingHasBeenUnublished($jobPosting);
$eventDispatcher->dispatch($event);
// L'information part alors dans RabbitMQ
On a donc un événement métier JobPostingHasBeenUnublished (Une offre d’emploi a été dépubliée).
Un événement (du latin evenio), indique que quelque chose s’est passé (il faut impérativement que la chose dont on parle soit déjà réalisée).
On souhaite alors que cet événement métier déclenche des actions, comme l’envoi d’un mail, ou la suppression de l’offre d’emploi dans un moteur de recherche, mais aussi dans notre moteur de recommendation, etc.
Chez nous, chaque événement, s’il veut être ingéré dans RabbitMQ, va implémenter une interface qui l’oblige à se décrire sous
la forme d’un triplet Sujet + Verbe + Prédicat.
Par exemple :
# triplet qui représente un événement
Utilisateur 123 career.job_publishing.delete JobPosting 456
Un triplet est une expression de la forme Sujet + Verbe + Prédicat, mais peut prendre des formes complexes :
<?php
// Un triplet simple
$event = new EventLog('Utilisateur 123', 'career.job_publishing.delete', 'JobPosting 456');
// Un triplet avec un prédicat complexe
class JobPosting implements Predicate
{
public function asPredicate(): array; // @implement me
public function asPredicateidentifier(): string; // @implement me
}
$jobPosting = new JobPosting(456);
$event = new EventLog('Utilisateur 123', 'career.job_publishing.delete', $jobPosting);
En général chaque élément du triplet est un objet qui implémente la bonne interface.
Dès lors, notre moteur va envoyer ce triplet à RabbitMQ.
Un énorme avantage de cette approche, c’est que l’on peut facilement retrouver l’événement qui a déclenché une action, et on peut le documenter très facilement : lorsqu’on génère notre documentation, savoir si un événement part dans le bus de données est très facile.
Standardisation des données via ProtoBuff.
À partir de ce moment, ce triplet va être sérializé en JSON via ProtoBuf, et être émis vers RabbitMQ.
Nous avons fait le choix de fortement rationaliser les noms des messages. Tous se terminent par l’un des suffixes suivants :
*.*.postlorsque l’événement implique une création*.*.putlorsque l’événement implique une mise à jour*.*.deletelorsque l’événement implique une suppression*.*.hitlorsque l’événement implique une visite (comme “voir une page”)
Pour plus de facilités, les schémas protobuf sont partagés entre les différents services et sont stockés dans un dépôt git séparé, récupérables via Composer.
L’émission
RabbitMQ est un passe-plat entre un outil qui émet des informations, et un ou plusieurs outils qui les consomment (consumers).
Il existe plusieurs stratégies de consommation, mais ce n’est pas l’objet de ce billet.
En très bref, RabbitMQ permet d’émettre des messages :
- vers une queue de messages (
queue) - vers un échangeur (
exchange)
Une queue est une sorte de base de données temporaire, dans les quelles les consumers vont chercher les messages à lire.
Un échangeur est comme un aiguilleur : à partir de règles de configuration, il va orienter chaque message vers une, ou plusieurs, queues. Il est ainsi en général préférable d’émettre via un échangeur plutôt qu’une queue, car ça offre beaucoup plus d’évolutivité. Un échangeur peut même dupliquer le message, pour l’envoyer dans plusieurs queues à la fois. C’est ce qu’on appelle le Multiplexing.
Tout se passe via du mapping très simple, à coup de détection de motifs dans le nom du message (routing key)
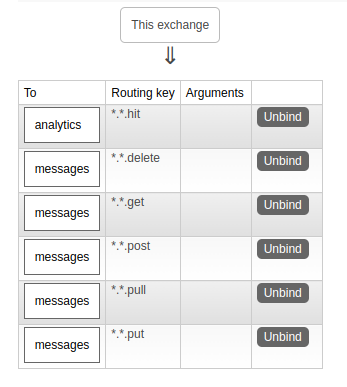
Ici, les messages qui matchent *.*.post sont dirigés vers une queue dédiée au traitement métier,
tandis que les messages *.*.hit sont dirigés vers un autre échangeur dédié à l’analytics,
qui lui-même se chargera de les diriger aux bonnes queues.
Exploiter le bus de données
Dans ce contexte il devient alors possible de spécialiser certaines briques de consommation pour les faire traiter des sujets bien précis. C’est ce qu’on appelle des micro-services (ici on ne parle pas d’API, mais bel et bien de services. Parfois ces services peuvent disposer d’une API, mais ce n’est pas une obligation).
On peut par exemple imaginer un service dédié à l’analytics, un autre à la synchronisation des données avec un service externe, un autre qui va faire de la consolidation, un autre qui va hydrater une DataPipeline en vue de l’exploiter en Big data, etc.
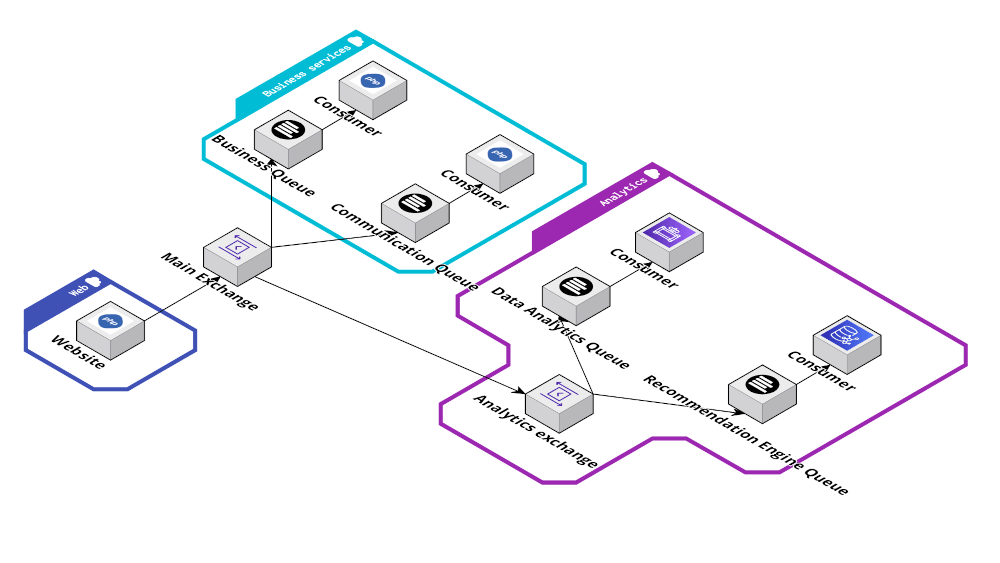
En multiplexant le message, d’échangeur en échangeur, on permet à chaque donnée d’être traitée autant de fois que nécessaire dans le système. Chaque service de consommation a une seule responsabilité simple, limitant sa complexité (la complexité ne porte plus alors sur le code, mais sur la compréhension des flux).
Choisir comment structurer la donnée
Dans un échange de données, il y a en gros 2 manières de voir la donnée (et donc de construire le message RabbitMQ) :
- ou bien elle est très légère. Elle ne contient que les infos minimales (un type et identifiant).
- ou bien elle est suffisante. Elle contient en elle-même les infos nécessaires à son traitement.
Chaque solution a ses inconvénients.
Si le message RabbitMQ est léger, il consomme moins de RAM. Mais chaque service de consommation doit avoir accès à une source de données complète (une base ou une API), ce qui renforce la dépendance entre les services et ralentit le traitement.
Si le message RabbitMQ est suffisant, il consomme beaucoup de RAM. Il faut être vigilant à ne pas le faire grossir inutilement, sous peine de saturer les serveurs. Par contre, le service de consommation n’a rien à faire de son côté, il lui suffit de déserialiser la donnée pour l’exploiter facilement.
J’avoue que je préfère avoir des données suffisantes. C’est, de mon expérience, de très loin plus simple et performant. C’est pour ça que j’aime beaucoup ProtoBuf, vu qu’il me permet de sérializer / déserializer des données complètes très facilement, sans me soucier de la technologie utilisée (PHP, NodeJS, Go…).
De mon point de vue, devoir aller chercher des informations complémentaires sur une donnée entraîne nécessairement des “micro-services spaghettis”, qui s’appellent tous les uns les autres et dans tous les sens. Mais il doit être toutefois possible d’y arriver de manière élégante.
Quelques exemples de ce qu’il est possible de faire
Les possibilités sont infinies.
En s’appuyant sur des événements métiers, on peut avoir une vue en temps réel de ce qui se passe dans une application. Chaque événement étant daté, il suffit de les lire dans l’ordre pour savoir ce qu’il se passe. Voici par exemple une capture d’un écran de suivi d’activité de production :
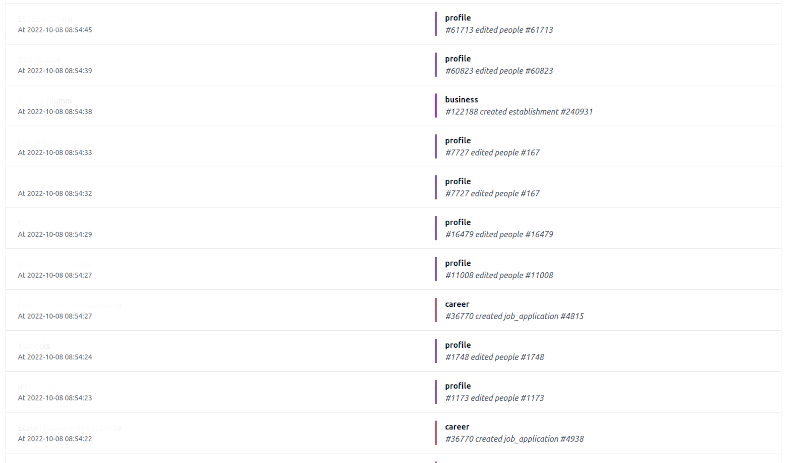
On s’en sert aussi pour hydrater un moteur de recommendations, en temps réel. Le consumer RabbitMQ devient alors la première brique de notre DataPipeline.
Encore un dernier exemple : on s’en sert pour synchroniser des données entre notre système d’information et celui de certains clients / fournisseurs, ce qui permet d’avoir en temps réel des informations à jour partout.
Limites
Ce paradigme a toutefois quelques limites.
D’abord, en termes de cohérence de données. S’appuyer sur RabbitMQ est facile, mais il existe d’autres types de bus plus “solides”. Par exemple, RabbitMQ ne garantie pas que les événements seront reçus dans l’ordre d’émission. Le message RabbitMQ d’une suppression d’utilisateur peut être reçu avant même de recevoir celui de création !
Le risque est minime dans un contexte à faible charge, mais sur de très gros volumes d’événements le risque est là.
Ensuite, en termes de code même : il nécessite de bien cibler ce qu’il est pertinent d’émettre dans le Bus. On est vite tentés de tout “bourrer” dans le bus de données, au cas où on en aurait besoin un jour. Il ne faut pas oublier que toute donnée utilise de la RAM et du CPU, qu’il convient d’utiliser avec parcimonie.
En bref
Une fois cela dit, c’est un pattern de conception extrêmement pratique et simple à mettre en oeuvre.
Il facilite la scalabilité, en rendant les traitements asynchrones simples et systématiques, et il rend possible l’isolation des responsabilités au sein des micro-services.
Ce n’est pas une solution miracle, mais pour l’avoir mis en place sur plusieurs gros projets, dans différents contextes pour lesquels il me semblait adapté, il rend bien service !
OctoFirst
Voyez où votre équipe coince
Le projet sur lequel je bosse en ce moment. Vos pull requests en disent déjà long : où l'équipe se grippe, comment l'activité se répartit entre bugs, features et refacto. OctoFirst en fait des signaux clairs, sans reporting à faire à la main.
Y jeter un œil, c'est gratuitAudit & Formation
Disponible sur Malt
Besoin d'un regard extérieur sur votre code ? J'accompagne les équipes PHP sur l'architecture, les tests et l'industrialisation, au rythme de vos projets.
Me trouver sur Malt© Jean-François Lépine, 2010 - 2026 · Flux RSS