Menu
Speech Embeddings et Pronunciation Detection : construire un pipeline IA local avec Wav2Vec2
Vous trouverez la version 🇬🇧 anglaise de cet article ici
- Construire un coach de prononciation local avec Wav2Vec2 et Dynamic Time Warping.
- Comprendre les bases : embeddings audio, distances, alignement temporel, phonèmes et visèmes.
- Un projet open source, concret et motivant pour progresser en anglais à l’oral.
Lire ou écrire ne me pose pas trop de problèmes, mais dès qu’il s’agit de parler, je me rends compte que ma prononciation n’est pas toujours claire.
ChatGPT est super pour le texte, mais les modèles génératifs actuels ne savent pas évaluer la prononciation.
Alors je me suis demandé : et si je construisais moi-même un petit coach ?
Un outil qui :
- m’écoute,
- compare ce que je dis à une référence,
- et me renvoie un retour clair et visuel.
C’est ce que je vais détailler ici, tout en expliquant simplement les briques IA derrière : embeddings, distances, DTW, phonèmes, visèmes.
Pourquoi comparer deux sons est si difficile ?
Un mot parlé n’est pas une suite de lettres, mais une onde sonore qui varie dans le temps :
- l’air vibre,
- la voix monte et descend,
- certaines parties sont longues, d’autres très courtes.
Même deux personnes qui prononcent exactement le même mot n’auront jamais deux courbes identiques.
La question centrale devient donc : comment comparer deux audios qui ne s’alignent pas parfaitement ?
L’approche choisie
Voici un aperçu de l’architecture que j’ai mise en place :
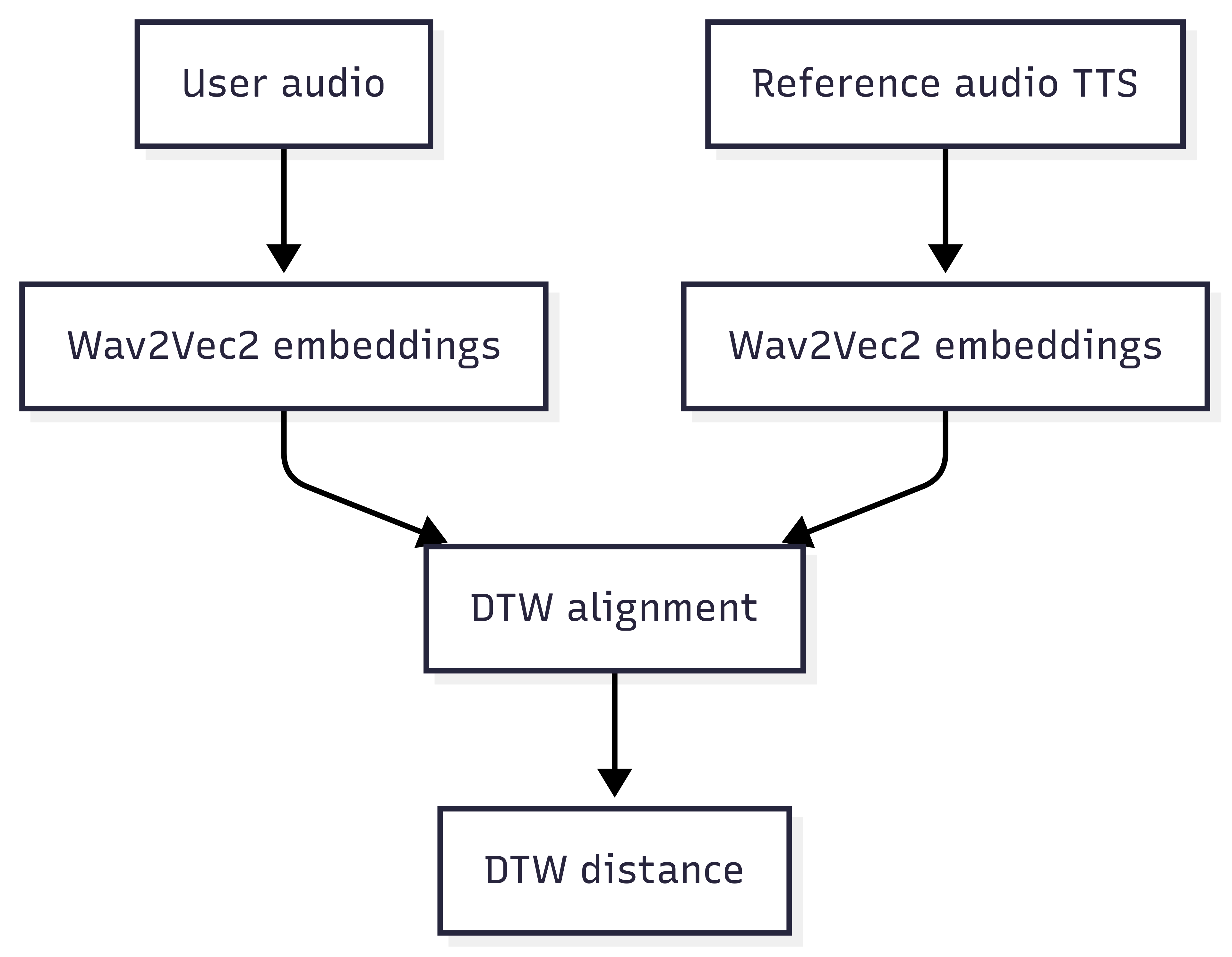
N’ayez pas peur, on va expliquer tous ces concepts pas à pas.
Transformer le son en nombres : les embeddings
Un ordinateur ne comprend pas les sons. Il ne manipule que des vecteurs de nombres.
- Un vecteur = une liste de nombres, par ex.
[0.2, -0.7, 1.1]. - Un embedding audio = une représentation condensée d’un petit morceau de son.
Avec Wav2Vec2, chaque tranche d’audio de quelques millisecondes est encodée en 768 nombres décrivant le timbre, l’énergie, l’articulation, etc.
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
def extract_embeddings(audio_waveform, sampling_rate=16000):
inputs = processor(audio_waveform, sampling_rate=sampling_rate,
return_tensors="pt", padding=True)
input_values = inputs.input_values.squeeze(0)
with torch.no_grad():
features = model(input_values).last_hidden_state
return features.squeeze(0).numpy()
En résumé :
- sons proches → vecteurs proches,
- sons différents → vecteurs éloignés.
Mesurer la ressemblance : les distances
Une fois deux vecteurs extraits, il faut mesurer leur proximité.
L’outil de base : la distance euclidienne.
Exemple simple entre [1,2] et [4,6] :
√((4-1)² + (6-2)²) = 5
Avec les embeddings audio, c’est le même principe mais dans un espace à 768 dimensions.
from fastdtw import fastdtw
from scipy.spatial.distance import euclidean
def compare_pronunciation(expected, actual):
expected_seq = get_phoneme_embeddings(expected)
actual_seq = get_phoneme_embeddings(actual)
distance, _ = fastdtw(expected_seq, actual_seq, dist=euclidean)
return distance
DTW : quand on ne parle pas à la même vitesse
Problème : un mot peut durer 0,5 seconde chez moi et 0,8 seconde dans la référence.
Si on compare naïvement, ça échoue.
La solution : Dynamic Time Warping (DTW).
Cet algorithme aligne deux séquences de vitesses différentes en “étirant” ou “compressant” le temps pour faire correspondre les parties similaires.
import numpy as np
def align_sequences_dtw(seq1, seq2):
distance, path = fastdtw(seq1, seq2, dist=euclidean)
aligned1, aligned2 = [], []
for i, j in path:
aligned1.append(seq1[i][0])
aligned2.append(seq2[j][0])
return np.array(aligned1), np.array(aligned2)
Résultat : une comparaison robuste, même si le rythme diffère.
Phonèmes et visèmes : entendre ET voir
Certains sons sont difficiles à distinguer à l’oreille.
Exemple : “think” vs “sink” (différence subtile entre /θ/ et /s/).
- Un phonème = le plus petit son distinctif (ex. /p/, /a/, /t/).
- Un visème = l’image de la bouche qui produit ce son.
Dans mon prototype, quand un mot est mal prononcé, je peux cliquer dessus et voir une animation de bouche qui montre la bonne articulation.
👉 Apprentissage plus concret : j’entends et je vois ce qu’il faut corriger.
(Documentation Microsoft sur les visèmes)
Le pipeline complet
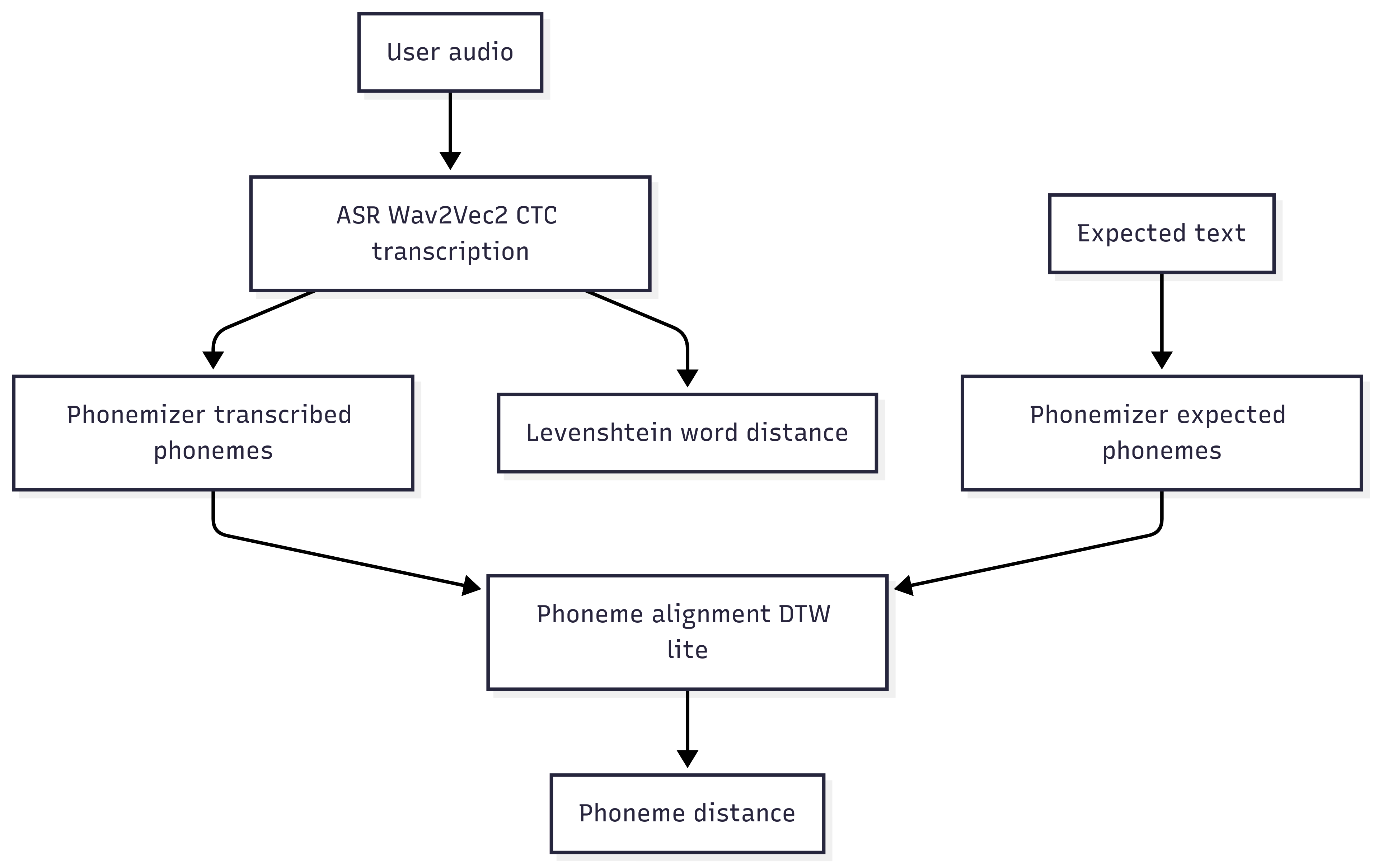
- J’écris un texte : “Hello, how are you?”.
- Le système génère une voix de référence (ex. gTTS).
- J’enregistre ma voix.
- Extraction des embeddings Wav2Vec2 pour les deux audios.
- Alignement avec DTW.
- Comparaison phonème par phonème.
- Feedback renvoyé :
- un score global (sur 100),
- une liste de mots mal prononcés,
- un feedback clair : “❌ Tu dois mieux prononcer : Hello, you”,
- et les visèmes correspondants.
Limites de l’approche
Soyons honnêtes :
- Wav2Vec2 n’est pas entraîné pour noter la prononciation → approximation.
- Voix de synthèse imparfaite → accent parfois artificiel.
- Visèmes simplifiés → animations trop discrètes comparées à une bouche réelle.
- Subjectivité persistante → la compréhension d’un natif reste la référence ultime.
Ce que ça apporte malgré tout
- Je peux m’écouter objectivement.
- J’identifie mes erreurs sans prof.
- Je dispose d’un feedback visuel.
- Et surtout : je garde la motivation à pratiquer.
Pistes pour aller plus loin
- Intégrer des modèles spécialisés de pronunciation scoring (API commerciales).
- Améliorer les visèmes avec de la 3D fluide.
- Ajouter la prosodie (intonation, accentuation, rythme).
- Étendre à d’autres langues.
- Évaluer des phrases longues (lecture, dialogue).
Conclusion
Je n’ai pas réinventé Duolingo. Mais j’ai construit un coach maison qui m’aide à progresser à l’oral.
La force vient de la combinaison :
- IA (Wav2Vec2) pour transformer la voix en vecteurs,
- algorithmes classiques (DTW) pour comparer,
- visuels pédagogiques (visèmes) pour corriger.
Un mélange de machine learning, de maths et de pédagogie, au service d’un objectif très concret : mieux parler anglais.
👉 Le code source est disponible sur GitHub.
Vos retours ou contributions sont bienvenus.
OctoFirst
Voyez où votre équipe coince
Le projet sur lequel je bosse en ce moment. Vos pull requests en disent déjà long : où l'équipe se grippe, comment l'activité se répartit entre bugs, features et refacto. OctoFirst en fait des signaux clairs, sans reporting à faire à la main.
Y jeter un œil, c'est gratuitAudit & Formation
Disponible sur Malt
Besoin d'un regard extérieur sur votre code ? J'accompagne les équipes PHP sur l'architecture, les tests et l'industrialisation, au rythme de vos projets.
Me trouver sur Malt© Jean-François Lépine, 2010 - 2026 · Flux RSS